Suite à la demande de Léon concernant un rapport publié sur le net mais retiré par la suite, je me suis dit qu’expliquer un peu les possibilités de navigation dans le net caché pouvait être une bonne chose.
L’archivage du net existe
Depuis 1996 environ, il existe un organisme Internet Archive dont le but est d’archiver le contenu du web entier afin de préserver le « savoir humain et l’accès au contenu à tous ». Cela bien sûr peut amener à des abus, vous vous en doutez, mais il n’est pas question ici de discutailler éthique ou droit à l’oubli: il s’agit de voir quel intérêt pratique l’archivage du web peut nous apporter.
-
-
- Votre hébergeur vous lâche, vous n’avez plus accès à votre ftp… il est possible de récupérer les pages web de votre site.
- Un débile mental profond saccage votre site, vous pouvez quand même retrouver des données online.
- Votre marque page envoie maintenant sur une page introuvable, il est possible de la retrouver
- Un rapport, document ou photos a été posté puis retiré, vous pouvez le retrouver
- Des textes injurieux, antisémites ou illégaux ont été postés puis effacés… on peut les retrouver.
-
L’archivage se fait principalement par des bots (ou robots) qui vont prendre des instantanés des pages web et mettre à disposition dans une sorte de wayback machine. Mais il existe aussi une autre possibilité: tous les moteurs de recherche ont un cache et conservent donc une version antérieure des pages web. Ainsi, on peut dire que, d’une manière un peu différente, Google est le plus grand archiviste du net pour la mémoire à court terme.
Concrètement comment je fais?
Vous pouvez effectuer une manipulation dans le moteur de recherche Google pour accéder à la version cache du lien.
La conservation d’une version cache d’une page Web, voire d’un site dans son ensemble, n’est jamais éternelle. Mais, tant qu’elle reste effective, l’existence des ces versions permet de contourner la censure, de remettre au vu et au su de tous une information que certains voudraient voir disparaître. Elle permet même de contourner, parfois, des protections mineures, comme de consulter les pages d’un forum normalement accessibles qu’à des visiteurs identifiés…
Lorsque vous utilisez un lien « En cache », vous n’allez plus être dirigé vers la page actuellement en ligne du site, vers sa dernière version, mais vers une copie fonctionnelle que Google a enregistrée lors de sa dernière sauvegarde dudit site.
Vous y retrouverez toutes les informations principales de la page d’origine, avec le plus souvent les pubs en moins mais toujours les images et les vidéos, et parfois quelques défauts dans l’affichage, la mise en page. Et vous aurez surtout à nouveau accès à la plupart des données que contenait cette page, et c’est tout ce qui importe.
Pour accéder à la version en cache d’une page, il faut cliquer, dans la zone de résultats qui nous intéresse, sur la petite flèche verte pointant vers le bas. Apparaît alors un menu déroulant nous proposant, si disponibles :
-
-
- de voir la page ciblée dans sa version cache (cliquer sur « En cache »)
- d’accéder à des contenus similaires à la page ciblée (cliquer sur « Pages similaires »)
- de partager la page ciblée sur notre profil Google+ (cliquer sur « Partager »)
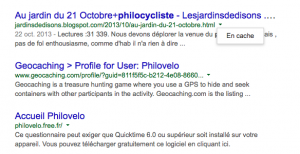
Le cache google accessible via la flèche verte Je vous illustre le propos avec cette image: si vous cliquez sur la petite flèche verte en bout du lien, vous verrez apparaître « En cache » ce qui permet de sélectionner la page web lors de l’enregistrement antérieur de Google. Très pratique pour retrouver une info quand le serveur ou le site est offline, par exemple.
-
Et Internet archive?
Pour cela, le plus simple est d’installer un plug-in sur votre navigateur. Exemple, Resurect Pages pour Firefox. Il va permettre de ressusciter les liens morts en fouillant dans les pages fantômes des caches ou des archives. Il peut utiliser la wayback machine ou alors le Coral Cache.
Quelles limitations?
Bien évidemment, tout ne peut être sauvegardé. Les sites ne sont pas forcément scrutés tous les jours. le cache navigateur est donc assez limité en terme de temporalité, quant à internet archives, il faut espérer 6 à 12 mois d’accessibilité, après c’est plus compliqué.
Comment puis-je archiver moi aussi ce qui m’intéresse?
Si vous avez peur que certains sites ou certaines pages qui vous sont très utiles disparaissent par faute d’hébergement, par censure ou par désintérêt de l’auteur, vous pouvez vous aussi les archiver avec un aspirateur de sites. Le principe est de recréer facilement et en local sur votre machine le site aspiré.
Exemple pratique d’une résurrection
C’est bientôt Pâques alors je vous montre en image une résurrection de lien mort (Alléluia!!!). J’utilise pour ce faire le module resurect pages 2.06 pour Firefox.
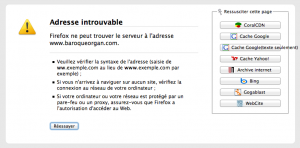
Mon marque page http://www.baroqueorgan.com/home.html m’envoie vers une erreur 404 et page introuvable.
Je choisis Archive Internet dans la liste de droite:

Le calendrier des instantanés disponibles est proposé, je choisis le 26 Mars 2012 (date avec cercle bleu).

Je retrouve bien la page d’accueil du site telle que sauvegardée ce jour-là.
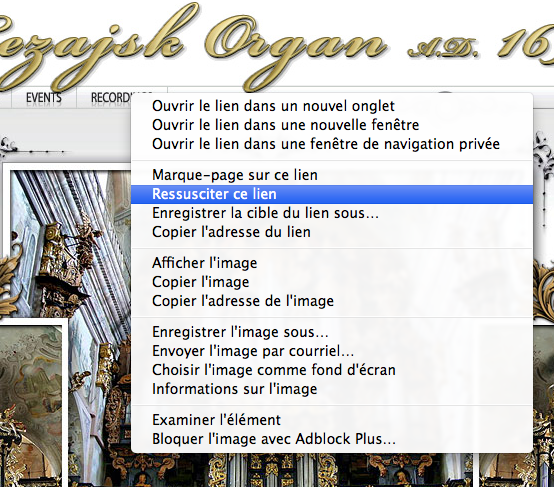
A noter que le plug-in permet l’ajout dans le menu contextuel « clic-droit » sur un lien de le ressusciter comme le montre l’illustration ci-après.
——
Pour aller plus loin:
http://obligement.free.fr/articles/retrouver_page_web.php
Merci Lapa pour ce matériel dont je vais tenter d’apprendre à me servir.
Il me semble qu’aux beaux jours de nos débuts , Lech a tenté de nous montrer que cela permettait de retrouver certaines pages de Maboul
Mais à l’époque comme aujourd’hui je ne comprenais pas grand chose à cet outil…
Je vais donc tenter un essai , lien après lien pour voir où tout ça me conduit.
DDDDD
Passionnant. Merci. Voilà des trucs super-utiles. C’est vrai que cela pourrait être drôle de retrouver pour Maboulvox les combats Zozos vs/ Momo ou même nous autres contre Popaul et Revelli… Je suis sûr que Furtif va se régaler.
Du coup, d’ailleurs, je me demande si on ne pourrait pas le republier sur Disons, ce rapport du policier. Faudrait arriver à joindre son auteur.
faut voir. Comme je le dis, la prise des instantanés ne permet pas de tout sauver. Un site avec beaucoup de trafic aura plusieurs prises de vues dans la journée (9 par exemple pour LeMonde.fr). Pour le site citoyen c’est plutôt un instantané tous les 3 jours…
Donc possibilité de récupérer des anciens articles retoqués ou supprimés, oui , mais de la à réussir à chopper tous les commentaires… difficile 😉
Oui, je confirme: j’ai quelques fois cherché à retrouver ds vieux comms ou des auteurs supprimés sur maboul, c’est peine perdu la plus grande partie du temps.
un autre exemple de résurrection : la page http://www.communautarisme.net/Entretien-de-Julien-Landfried-a-la-revue-Utopie-critique-l-antiracisme-mediatique-est-une-strategie-de-substitution-de_a973.html qui est une interview très juste concernant l’antiracisme médiatique (et toujours d’actualité). N’est plus retrouvable (trop ancienne sans doute pour le serveur).
et bien on la retrouve ici: http://web.archive.org/web/20071021061250/http://www.communautarisme.net/Entretien-de-Julien-Landfried-a-la-revue-Utopie-critique-l-antiracisme-mediatique-est-une-strategie-de-substitution-de_a973.html
profitez-en, c’est très intelligent ce qui est dit 🙂
« -si tant est que la communauté existe »
Là, on est certain que ce n’est pas la morice team qui a écrit car eux disent « si tenté est » 😆
Effectivement. Par exemple :